Cell Ranger7.1, printed on 03/29/2025
While most of the antibody-related metrics and counts are computed in parallel with their gene expression counterparts, there are some unique aspects of protein libraries that require specific analysis steps in Cell Ranger.
Note:
|
| To learn about the Cell Ranger algorithm used to process Barcode Enabled Antigen Mapping (BEAM)/ Antigen Capture libraries, visit the Algorithms section of the 5' Immune Profiling website. |
Protein aggregates in antibody staining experiments can result in a few GEMs having significantly elevated UMI counts. To tackle this issue, a two-step process is implemented to identify and exclude the barcodes associated with these problematic GEMs.
First, as part of the UMI counting pipeline, Cell Ranger identifies pairs of UMIs that differ by only one base (i.e., having a Hamming distance of one) and applies a process called UMI correction. During this step, reads associated with these UMIs are merged into a single UMI count by correcting the UMI with fewer reads using the UMI with more reads. Although such correction events are typically uncommon, there have been instances where correction rates are unusually high in Antibody Capture libraries. This phenomenon consistently correlates with extremely high UMI counts. Such high UMI counts can cause saturation of the UMI space, resulting in false UMI corrections. Protein aggregates represent a prominent cause of these elevated UMI counts and correction rates.
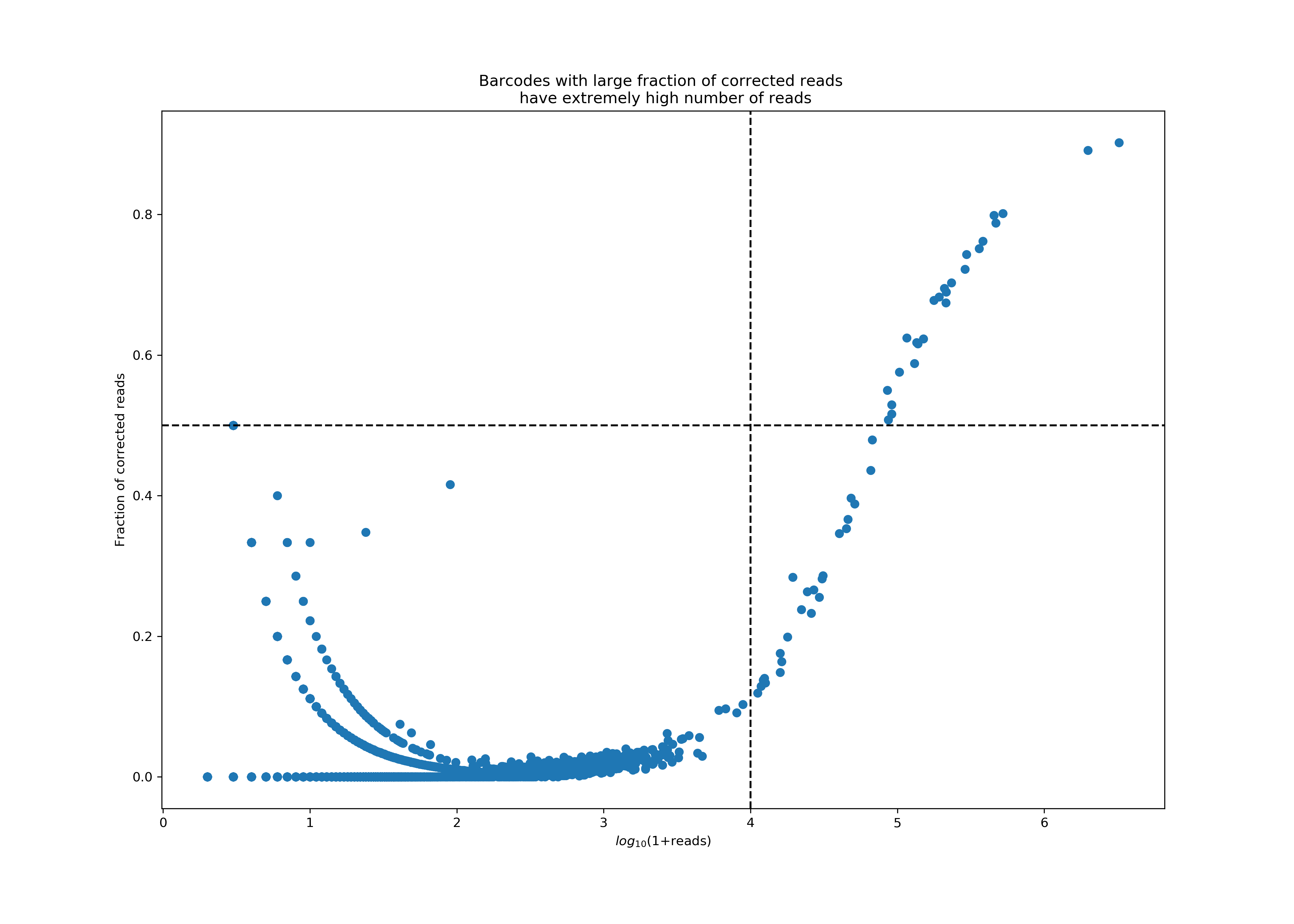
This accompanying plot shows an extreme case of protein aggregation, where a few barcodes account for nearly 77% of all reads, with extremely high correction rates in these reads. Currently, a barcode is classified as an aggregate if it has more than 10K reads, 50% of which were subject to correction.
Additionally, Cell Ranger employs protein counts to directly detect aggregation events alongside monitoring UMI correction events. The underlying insight is that large antibody panels are commonly employed to stain a diverse range of cell types. Consequently, observing high counts of numerous unrelated proteins within a GEM serves as an indicator of protein aggregates.
This algorithm is activated when five or more antibodies (or antigens, dextramers, or other features designated as "Antibody Capture" in the Feature Reference) each have at least 1,000 counts. Based on the total number of such features, Cell Ranger dynamically determines the required percentage for these features to be detected within a GEM to warrant further consideration. Subsequently, if the necessary number of antibodies exceeds their predefined thresholds for high counts (currently defined as being among the 25 highest counts across all GEMs), the GEMs are flagged as protein aggregates.
This accompanying plot exemplifies an aggregate barcode. Unrelated antibodies, such as CD3, CD19, CD14, CD56, and even mouse isotype controls IgG1 and IgG2a, are enriched in the orange barcode (top right corner), which the pipeline identifies as an aggregate.
<table class="table table-bordered">
<tr>
<td><img src="/img/single-cell-gex/antibody-aggregates1.png" style="width: 276px; height:200px"/></td>
<td><img src="/img/single-cell-gex/antibody-aggregates2.png" style="width: 276px; height:200px"/></td>
<td><img src="/img/single-cell-gex/antibody-aggregates3.png" style="width: 276px; height:200px"/></td>
</tr>
</table>
Cell Ranger combines the aggregate barcodes identified from both aforementioned steps and removes them from the final feature-barcode matrix. The fraction of reads associated with these barcodes is reported as the "Antibody: Fraction Reads in Aggregate Barcodes" metric in the web summary. Furthermore, two related metrics are available in metrics_summary.json: "Antibody: Number of Aggregate Barcodes" indicates the number of detected aggregate barcodes, while "Antibody: Fraction Reads that have Corrected UMIs" represents the fraction of all reads that underwent a correction event.
In order to reduce the gene expression matrix to its most important features, Cell Ranger uses Principal Components Analysis (PCA) to change the dimensionality of the dataset from (cells x genes) to (cells x M) where M is a user-selectable number of principal components (via num_principal_comps). The pipeline uses a python implementation of the IRLBA algorithm, (Baglama & Reichel, 2005), which we modified to reduce memory consumption. For samples where Antibody Capture is an input library, the pipeline will slice out the feature counts from the full matrix and perform a PCA on these log-transformed antibody counts, log2(count + 1).
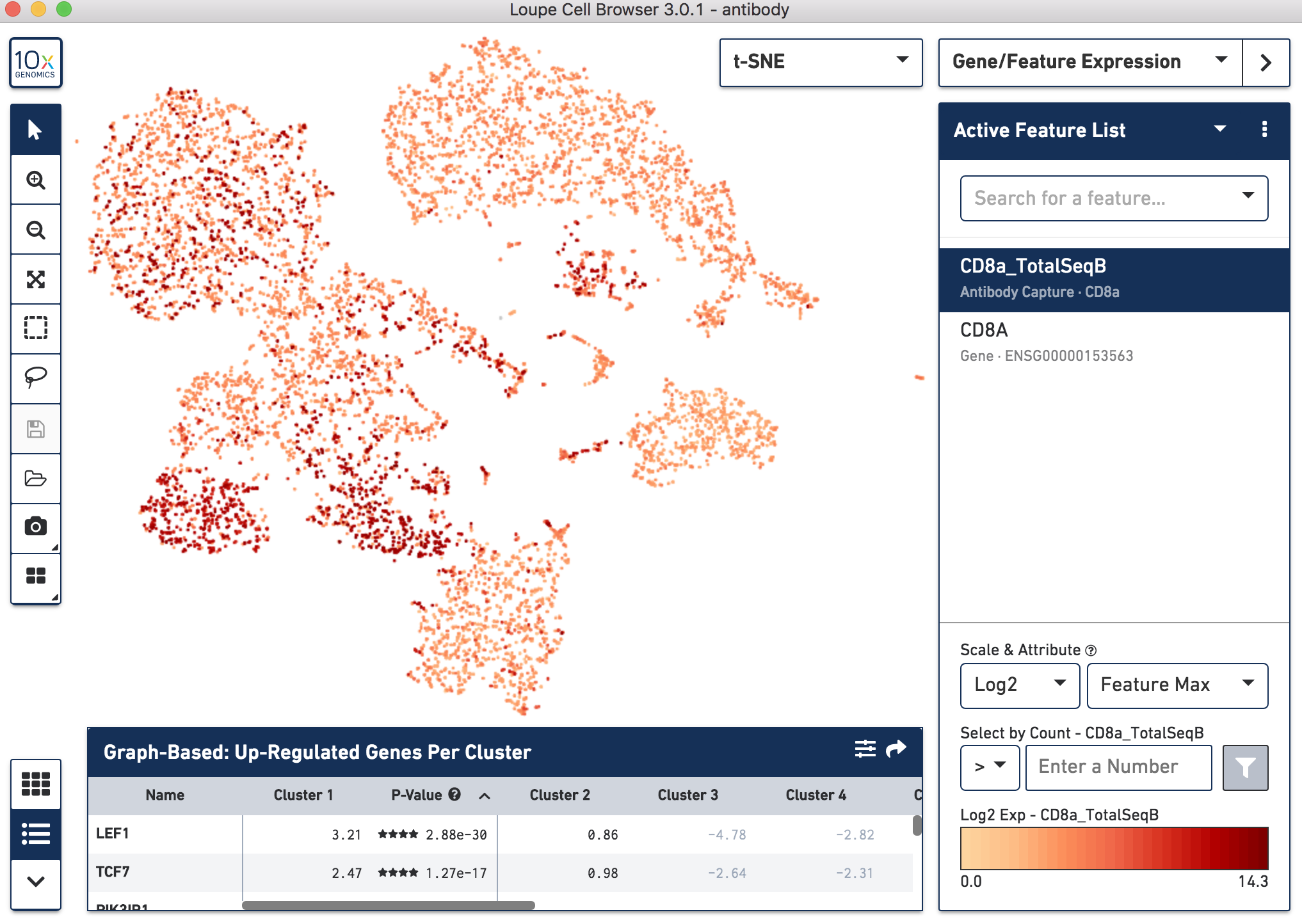
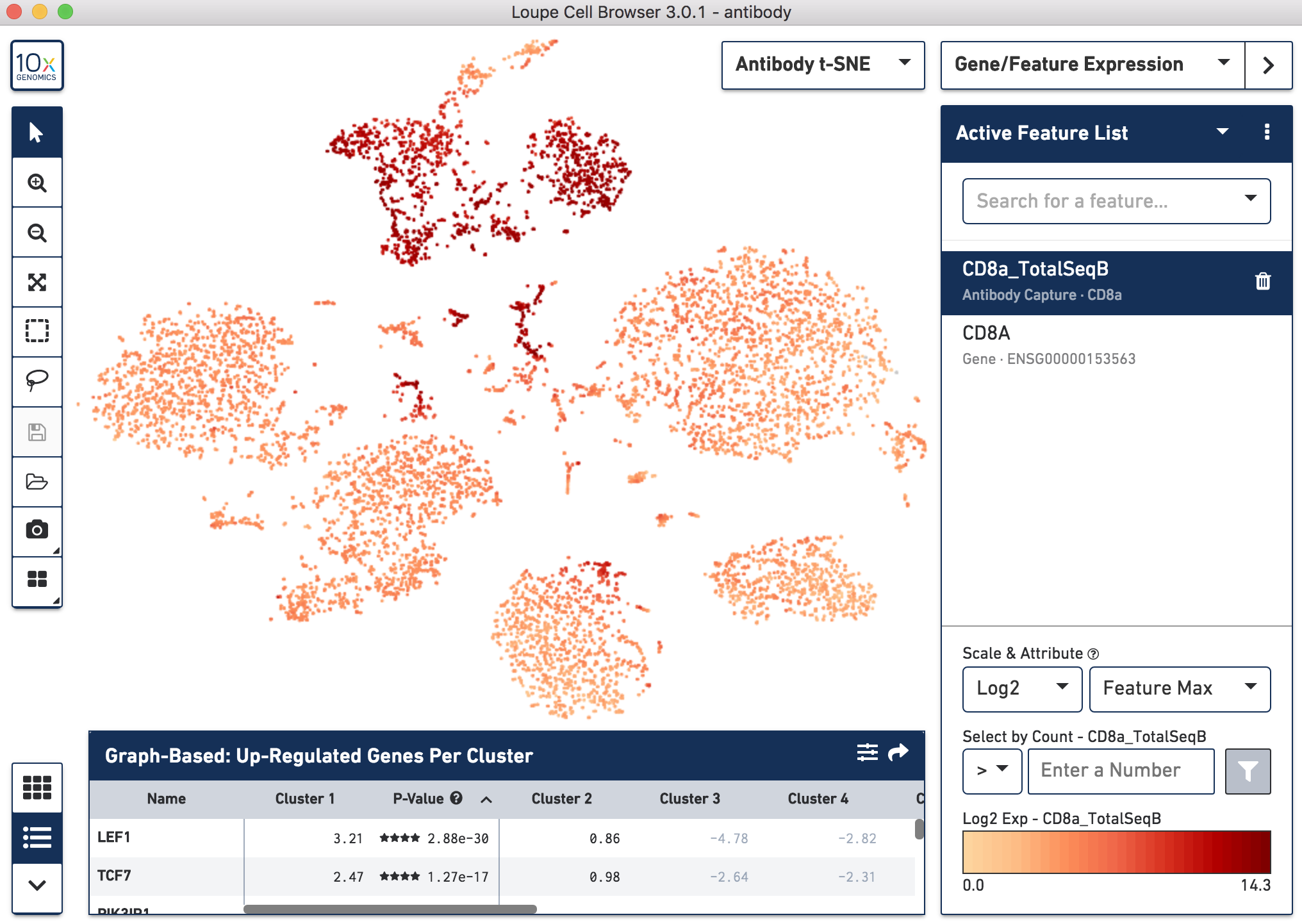
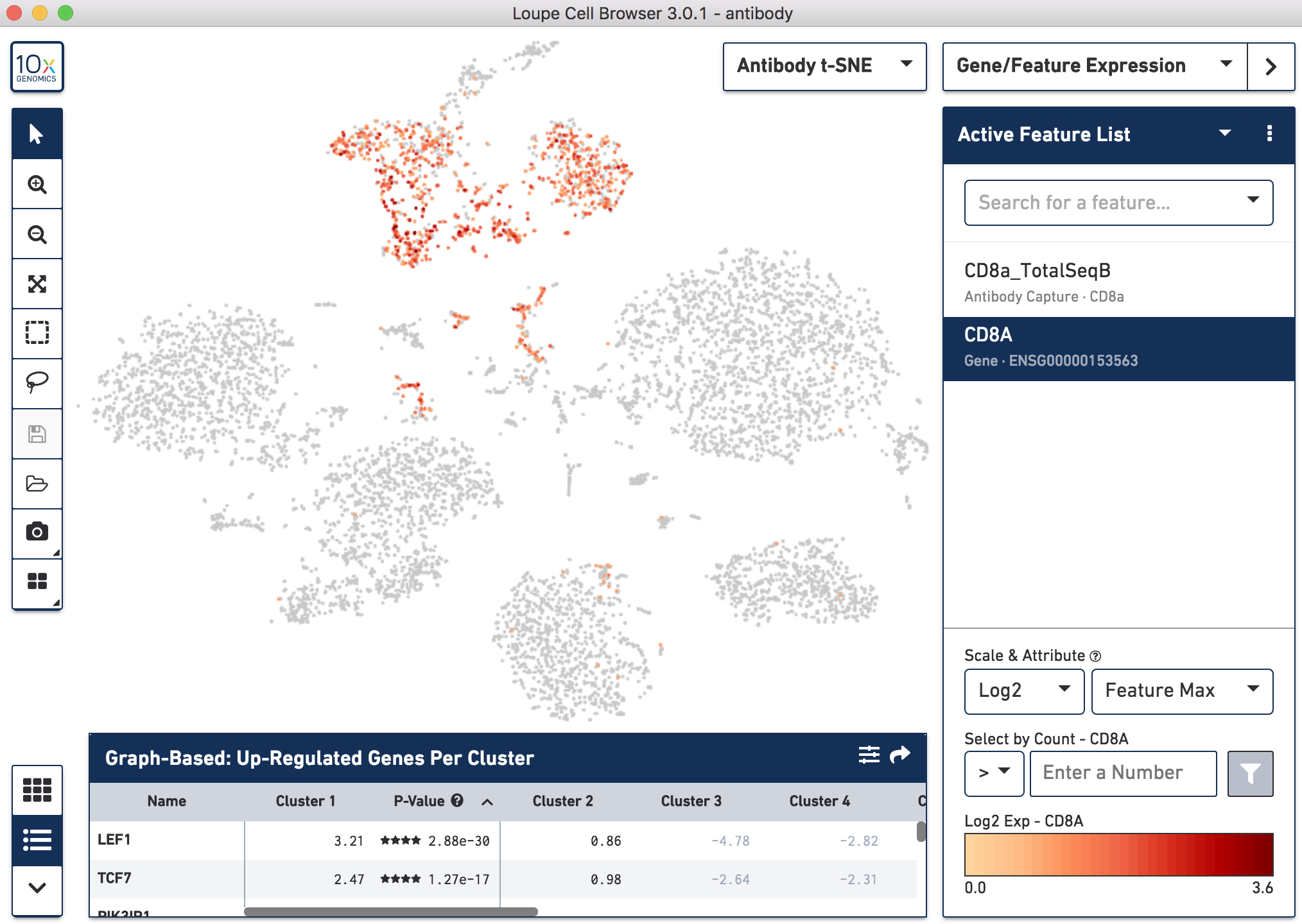
Since cell surface proteins offer a unique and complementary view of the cell types on top of the genes they express, Cell Ranger runs a popular t-distributed Stochastic Neighbor Embedding (t-SNE) algorithm to visualize the protein counts in 2-D space. For samples where Antibody Capture is an input library, the pipeline will slice out the feature counts from the full matrix and perform a t-SNE on these log-transformed antibody counts, log2(count + 1) (unlike the gene expression part of the feature-barcode matrix, where t-SNE is run on the PCA-reduced space from raw counts). These t-SNE projections can then be visualized with Loupe Browser versions 3.0 and later.
Below, the left panel shows a traditional t-SNE with gene counts only, overlaying the counts of CD8a antibody. The middle panel shows CD8a protein expression overlaid on t-SNE projections computed on antibody counts only. The right panel shows the expression of CD8A gene on the antibody-derived t-SNE projections for comparison.
 |
 |
 |
Cell Ranger also supports visualization with UMAP (Uniform Manifold Approximation and Projection), which estimates a topology of the high dimensional data and uses this information to estimate a low dimensional embedding that preserves relationships present in the data (McInnes et al, 2018). The pipeline uses the python implementation of this algorithm by McInnes et al (2018). UMAP coordinates are available in the pipeline output analysis/umap directory. Similar to t-SNE plots, in samples with Antibody Capture reads, the pipeline will slice out these feature counts from the full feature-barcode matrix and perform UMAP on log-transformed antibody counts, log2(count + 1).
Baglama J and Reichel L. Augmented implicitly restarted Lanczos bidiagonalization Methods. SIAM Journal on Scientific Computing 27: 19–42, 2005.
McInnes L, Healy J, and Melville J. UMAP: Uniform Manifold Approximation and Projection for dimension reduction. arXiv, 2018.