Top searches
Filter datasets
10x Genomics product
Sample type
Datasets (No datasets found) | Product | Species | Sample type | Cells or nuclei | Preservation |
|---|

10k Human DTC Melanoma, Chromium GEM-X Single Cell 3'
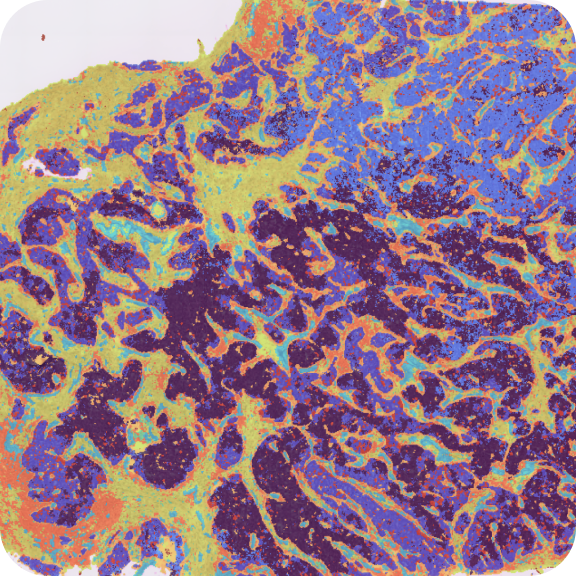
Visium HD Spatial Gene Expression Library, Human Breast Cancer (Fresh Frozen)
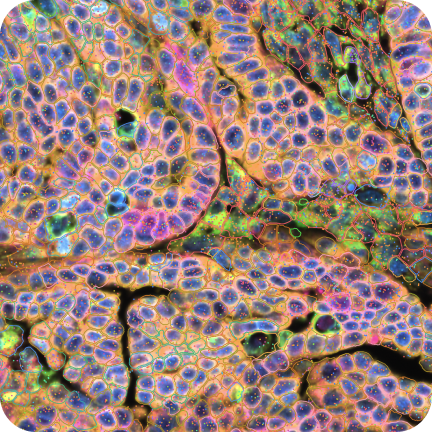
FFPE Human Ovarian Cancer with 5K Human Pan Tissue and Pathways Panel plus 100 Custom Genes
Datasets (No datasets found) | Product | Species | Sample type | Cells or nuclei | Preservation |
|---|